Alta disponibilidad para Linux
Juan Pedro Paredes
juampe@retemail.es
Este documento relata los principios bÃsicos de la alta disponibilidad, ademÃs de dar un enfoque a la problemÃtica que ha llevado el desarrollo de estos sistemas.
Luego se enumeraran las caracterÚsticas que hacen de Linux un sistema operativo robusto para su uso en estos sistemas. AdemÃs se comentaran diversas soluciones ya creadas.
Introducciµn
Actualmente Linux es conocido, como un sistema operativo estable; la problemÃtica se genera cuando el hardware, no es tan fiable como se desearÚa. En la mayorÚa de los casos, cuando un sistema falla normalmente es debido a un fallo de hardware o a un fallo humano (debido a un error en la administraciµn del sistema).
En los casos en que un fallo hardware provoca graves consecuencias, debido a la naturaleza del servicio (aplicaciones crÚticas), se implementan sistemas tolerantes a fallos (fault tolerant µ FT); en los cuales, el servicio esta siempre activo. El problema de estos sistemas, es que son extremadamente caros y normalmente no hay presupuesto. AdemÃs suelen ser soluciones cerradas, totalmente dependientes de la empresa contratada. Se suele poner un servidor tolerante a fallos, varias interfaces de red, con tomas de alimentaciµn redundantes y climatizaciµn especial.
Los sistemas de alta disponibilidad (high availability µ HA), intentan obtener prestaciones cercanas al la tolerancia a fallos, pero a un precio muchÚsimo mÃs interesante. Esta es una opciµn, que la ha hecho crecer en importancia dentro del mundo empresarial. La alta dsiponibilidad està basada en la replicaciµn de elementos, mucho mÃs baratos que un sµlo elemento tolerante a fallos. Naturalmente, si hablamos de replicar servidores, hablaremos de un clºster d e alta disponibilidad (ver Figura 2). Sistemas tolerantes a fallos los podemos encontrar en entornos muy crÚticos, tales como una central nuclear o el sistema de navegaciµn de una aeronave moderna.
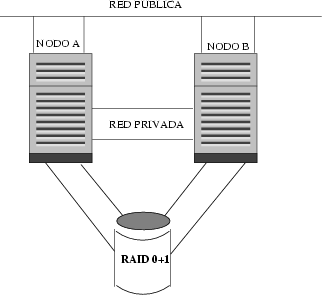
Sistemas de alta disponibilidad y sistemas tolerantes a fallos
En un sistema tolerante a fallos, cuando se produce un fallo hardware, el hardware asociado a este tipo de sistema es capaz de detectar el subsistema que falla y obrar en consecuencia para restablecer el servicio en segundos (o incluso dÕcimas de segundo). El cliente del servicio no notarà ningºn tiempo de fuera de servicio. En los sistemas de alta disponibilidad existen los tiempos de fuera de servicio; son mÚnimos pero existen, van desde 1 minuto o menos hasta 5 o 10 minutos, segºn sea el caso. En teorÚa esta es la ºnica diferencia entre ambos, pero en los ºltimos aþos, se ha ido acercando la idea de alta disponibilidad a la idea de tolerancia a fallos, debido al abaratamiento de hardware, y de ciertas tecnologÚas que han ido surgiendo. Estas tecnologÚas han evolucionado de tal forma, que han logrando que subsistemas donde habÚa que recurrir a la alta disponibilidad ahora, se puede lograr tolerancia a fallos a bajo precio. De todos modos en un sistema (como veremos en la siguiente secciµn) hay muchos elementos y subsistemas, y algunos subsistemas tolerantes a fallos siguen siendo demasiados caros.
En la mayoria de los anÃlisis, que se hacen de un sistema de servicio, si la aplicaciµn puede estar un mÚnimo tiempo fuera de servicio, y podemos permitir que el cliente pierda la sesiµn o la conexiµn, temporalmente, la alta disponibilidad es una opciµn muy apropiada. Hay soluciones de alta disponibilidad en las cuales las conexiones se mantienen y las sesiones se recuperan.
Gracias al equipo de desarrollo de linux-ha, en especial a Alan Robertson y a Horms quienes han hecho un trabajo excelente y constante en el Ãrea de la alta disponibilidad para Linux.
Gracias al grupo SERA, sin el cual este documento no serÚa posible.